github
操作系统
labview
Tableau
漏洞
easyui
luajit
充放电
后断开发
资损
卷积神经网络
RE理论干扰源的分析
sass
服务容错
比较两个宽字符串的字符
MySQL集群
流量运营
BCG
数值微分
社媒营销
self-attention
2024/4/11 15:29:01
【Transformer系列】深入浅出理解Attention和Self-Attention机制
一、参考资料
课件:10_Transformer_1.pdf 视频:Transformer模型(1/2): 剥离RNN,保留Attention
二、Attention without RNN
Attention模型可以看到全局的信息。 本章节以 Seq2Seq( (encoder decoder)) 模型为例&…

文献阅读:Synthesizer: Rethinking Self-Attention in Transformer Models
文献阅读:Synthesizer: Rethinking Self-Attention in Transformer Models 1. 文章简介2. 核心方法 1. Vanilla Self-Attention (V)2. Dense Synthesizer (D)3. Random Synthesizer (R)4. Factorized Model 1. Factorized Dense Synthesizer (FD)2. Fact…
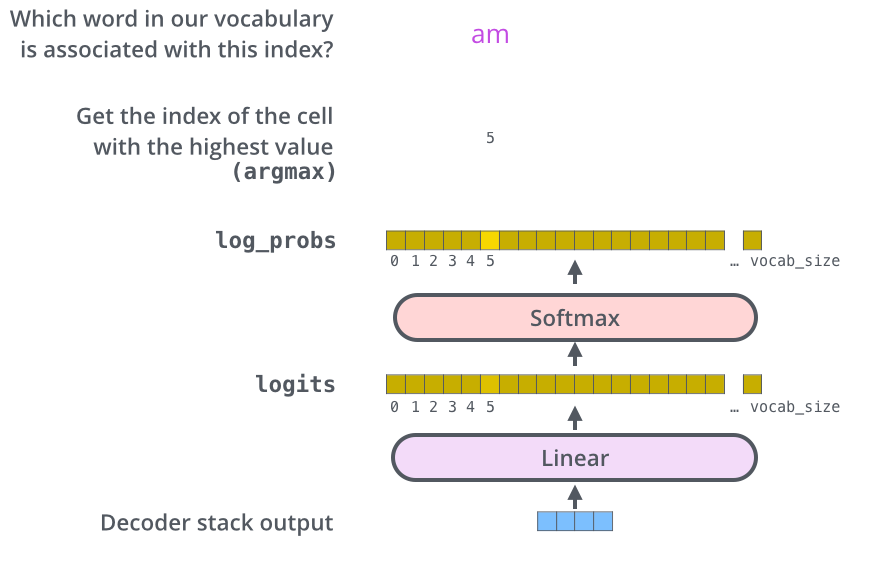
Transformer实战-系列教程2:Transformer算法解读2
🚩🚩🚩Transformer实战-系列教程总目录 有任何问题欢迎在下面留言 Transformer实战-系列教程1:Transformer算法解读1 Transformer实战-系列教程2:Transformer算法解读2
5、Multi-head机制
在4中我们的输入是X&#x…

一文详解Softmax的性质与Self-Attention初步解析
概述
最近研究超平面排列(Hyperplane Arrangement)问题的时候,发现ReLU有其缺陷,即举例来说,ReLU 无法使用单一的超平面将分离的所有数据,完整的输出,即只会输出半个空间映射的数据,而另一半空间的数据被置…
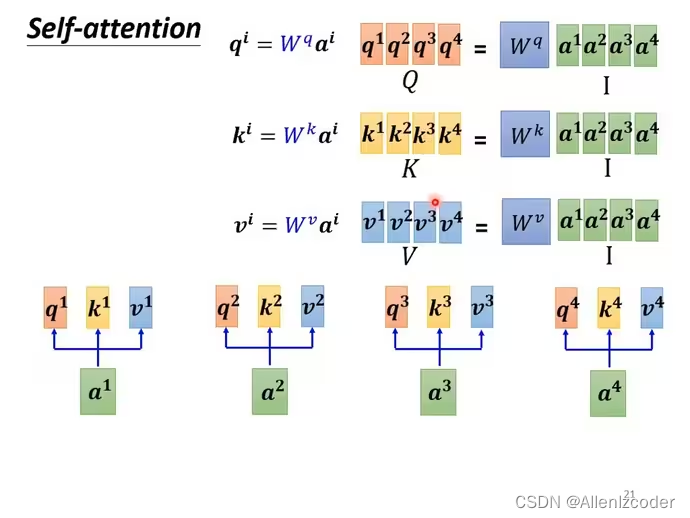
self-attention(上)李宏毅
B站视频链接
word embedding
https//www.youtube.com/watch?vX7PH3NuYW0Q self-attention处理整个sequence,FC专注处理某一个位置的资讯,self-attention和FC可以交替使用。
transformer架构 self-attention的简单理解 a1-a4可能是input也可以作为中…

Transformer实战-系列教程1:Transformer算法解读
现在最火的AI内容,chatGPT、视觉大模型、研究课题、项目应用现在都是Transformer大趋势了
1、传统的RNN Transformer是基于RNN改进提出的,RNN不同于CNN、MLP是一个需要逐个计算的结构来进行分类回归的任务,它的每一个循环单元不仅仅要接受当…
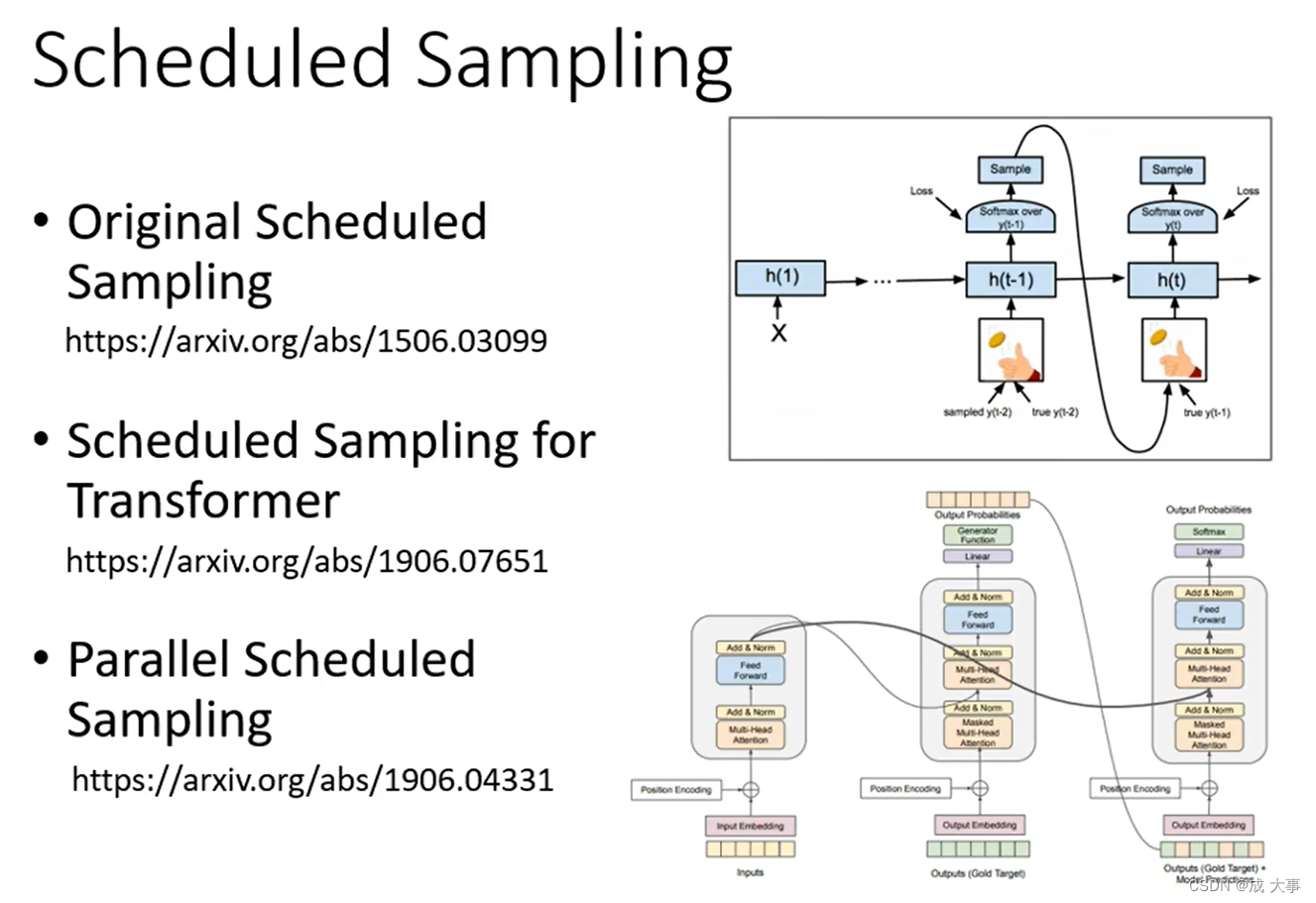
Transformer-深度学习-台湾大学李宏毅-课程笔记
目录 参考Seq2seqSequence-to-sequence(Seq2seq)适用任务语音识别机器翻译语音翻译语音合成聊天机器人自然语言处理硬解任务:文法分析硬解任务:多标签分类硬解任务:目标检测 Sequence-to-sequence(Seq2seq&…

【Transformer 相关理论深入理解】注意力机制、自注意力机制、多头注意力机制、位置编码
目录前言一、注意力机制:Attention二、自注意力机制:Self-Attention三、多头注意力机制:Multi-Head Self-Attention四、位置编码:Positional EncodingReference前言
最近在学DETR,看源码的时候,发现自己对…

SAM Self-Attention based Deep Learning Method
一、Why(Research Background)
网络流量分类根据协议(如超文本传输协议或域名系统)或应用程序(如脸书或Gmail)对流量类别进行分类。其准确性是一些网络管理任务(如服务质量控制、异常检测等)的关键基础。为了进一步提高流量分类的准确性,最近的研究引入了基于深度学习的方法…
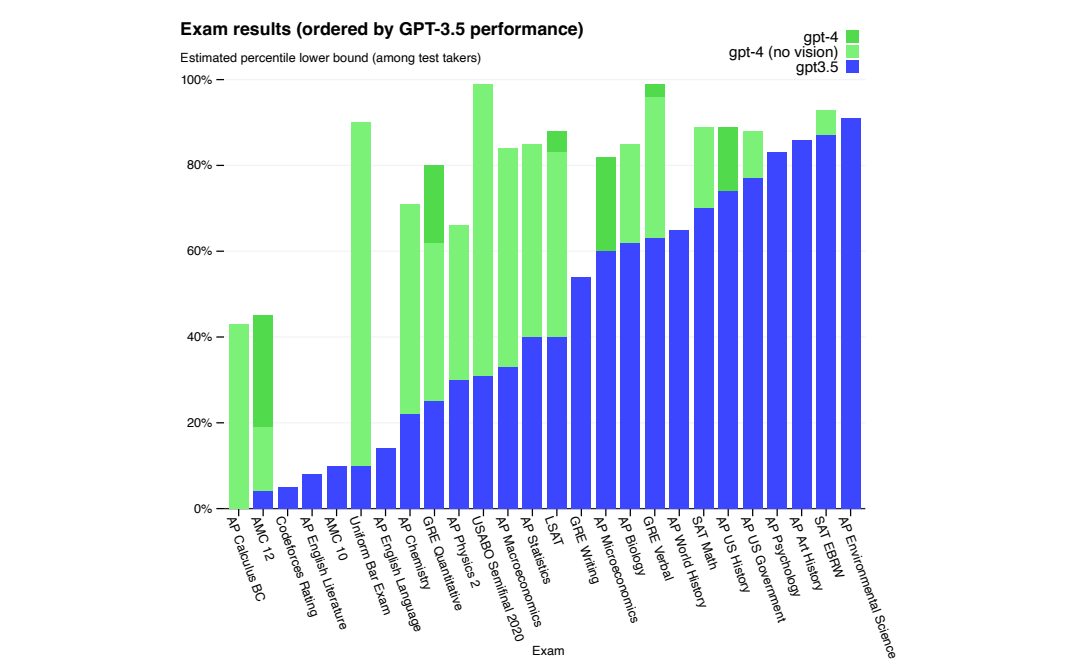
OpenAI开发系列(二):大语言模型发展史及Transformer架构详解
全文共1.8w余字,预计阅读时间约60分钟 | 满满干货,建议收藏! 一、介绍
在2020年秋季,GPT-3因其在社交媒体上病毒式的传播而引发了广泛关注。这款拥有超过1.75亿参数和每秒运行成本达到100万美元的大型语言模型(Large …
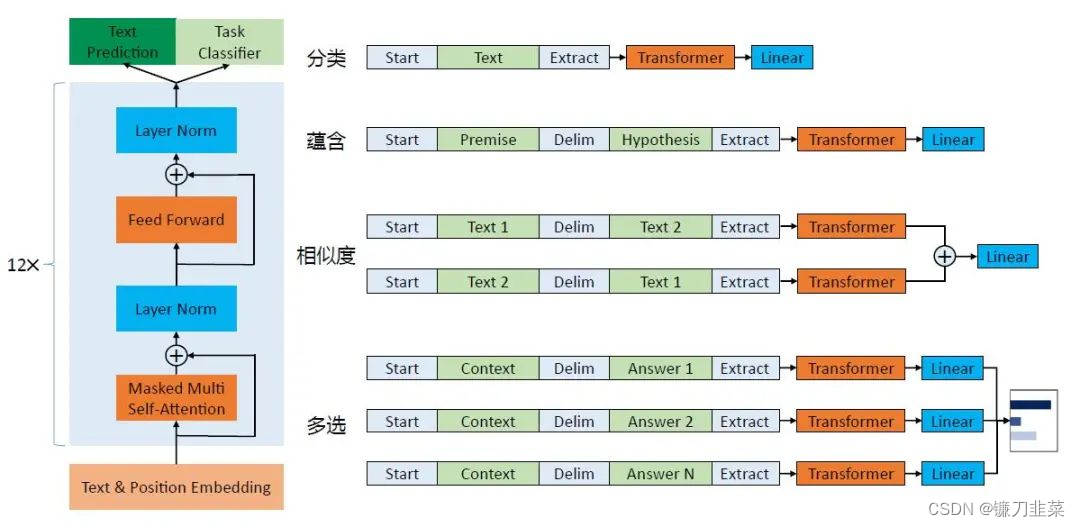
【AI理论学习】语言模型:掌握BERT和GPT模型
语言模型:掌握BERT和GPT模型 BERT模型BERT的基本原理BERT的整体架构BERT的输入BERT的输出 BERT的预训练掩码语言模型预测下一个句子 BERT的微调BERT的特征提取使用PyTorch实现BERT GPT模型GPT模型的整体架构GPT的模型结构GPT-2的Multi-Head与BERT的Multi-Head之间的…
文本分类 之 带有selfAttention的词向量平均模型
这是一个文本分类的系列专题,将采用不同的方法有简单到复杂实现文本分类。 使用Stanford sentiment treebank 电影评论数据集 (Socher et al. 2013). 数据集可以从这里下载 链接:数据集 提取码:yeqw 代码请参考:文本分类
文本分类…